This is a beginner level introduction to Structured Query Language (SQL). In this article you will learn following concepts:
- History of relational databases (RDBMS) and SQL
- The concept of tabulating data in rows and columns.
- Structure of a simple SQL statement
- Understand the flow of query execution and components of the SQL statement such as select, where, group by, order by clauses.
History of relational databases (RDBMS) and SQL
Like many other inventions, the history of SQL can be traced back to the Apollo moon program. NASA was working with thousands of vendors. The coordination was becoming challenging. NASA asked IBM (since Oracle wasn’t yet born) to develop a information management system (IMS) for information storage and quick retrieval of vendors and parts.
IMS system was a hierarchical database management system. For example, le us assume that the hierarchy is defined as follows.
Vendors -> Invoices -> Parts
The system described above is designed assuming a vendor can send multiple invoices and each invoice can contain one or more parts. The problem is that the same part can be supplied by multiple vendors. To model a single part and multiple vendors, we will need to define another separate relationship.
Example query for looking up the parts will be something like “who are the vendors who can supply PART001?”
Since the hierarchy we defined earlier begins with “Vendors” we cannot query the parts. Another different hierarchy needs to be defined to enable this querying capability.
OK. That was the first iteration of modern database management systems.
Note: IMS hierarchical database system is still in use today, mainly by some financial companies.
The shortcomings of IMS, led to the invention of relational databases and the seminal paper by Codd, “A Relational Model of Data for Large Shared Data Banks“. Based on this work, a number of relational databases (including Oracle) were released in 1970 and the early 1980.
After learning about the model by Codd, SQL programming language was invented at IBM in the early 1970s.
What is a Relational Database?
Relational databases separate data elements from their relationships. What does that mean?
Let’s say you are preparing a database of what your friends had for lunch. You might write something like this:
John ate broccoli
Ann ate pasta.
Joy ate pizza & soup.
There are two distinct entities. Person and Food. There is a one-to-many relationship between person and the food. In the most simplistic way, you could represent this data as follows:
person, food
john, broccoli
ann, pasta
joy, pizza,soup.
Notice that Joy ate two things but there is a single record for it. Such comma separated values make querying difficult. So we use, what is known as normalization.
What is data normalization?
Normalization is the process of separating a complex data record into its component real-world entity so that there is no data duplication and a single cell represents a single value.
In the person food example above, we can see that there are two entities: person and food.
Joy ate Pizza
Joy ate Soup.
The 1st normal form recommends that every cell should have a single value. In other words, don’t combine your shoe size and waist size into a single line separated by comma or other punctuation.
If you are interested in further understanding the process of data normalization, this article by Fred Coulson is a great resource.
Following the process of normalization, we arrive at the following third normal form.
Key Highlights:
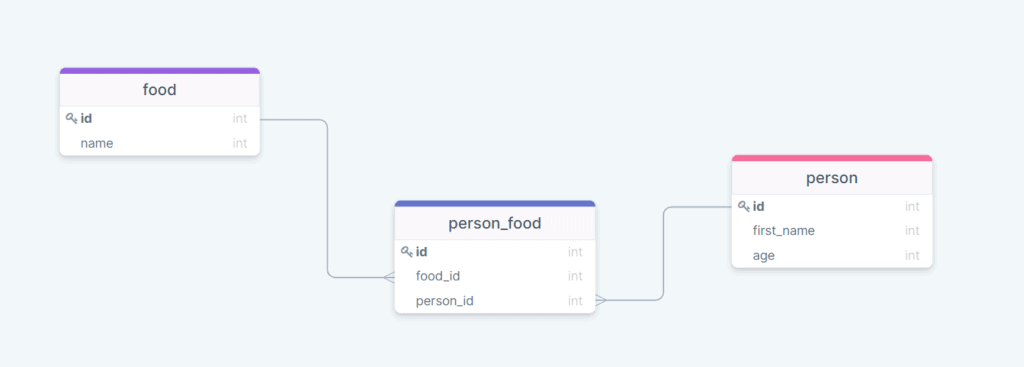
- Notice that both person and food are independent entities ( or things in the real-world). Both can exist without the presence of another. Who eats what represents the relationship between these two things and modelled in the person_food table.
- In hierarchical structures, representing one entity without the presence of another is challenging.
What is the Structure of a SQL Command?
Let take the example favorite color of kids in a residential neighborhood in Washington DC. There are 7 kids in this community. Their ages are from 5 to 9.
We can either represent them in a visual or in the textual format. Let us choose the visual format.







As you can see above, if we wish to represent hundreds of kids visually, it will take a few hours. The other option is the textual format.
For example,
name: Tina, age: 6, gender: female, color: red, score: 90
name: Mary, age: 7, gender: female, color: yellow, score: 84
Storing data in textual format is significantly quicker than visual format. Drawbacks include slow search and inability to perform mathematical operations on numerical data. If we wish to store large quantity of data that is easy to query & search, we need to use a structure.
The closest analogy is an unorganized (or messy) closet. If you wish to find your socks in this closet, it will take a few minutes. The same socks can be found in seconds if there is a dedicated shelf for it.
Let’s put this information in a structure. This data is about kids. Each kid is then called an entity. Each entity maps to a record in the database. We have information about kid such as their favorite color, gender, and their score. Each of this is an attribute. If we were to organize this information in a tabular format, we will have a table as shown below.
Separation of individual attributes into individual columns enables us to use specific data types for that column. This structure makes to possible to perform mathematical operations on relevant attributes (e.g. score, age etc.)

The data in tabular format can then be stored in a relational database (e.g. MySQL, Oracle). We can query it using SQL queries. Let us call this table “kids_in_washington”
What are the Components of an SQL Query?
The basic components of a SQL query are:
- select clause – required. attributes/columns
- From clause – required. table name
- Where clause – optional. filtering expression (e.g. name begins with ‘a%’ or a number is higher than 10)
- group by and having clause – optional. Required if using aggregate expressions (e.g. min, max etc)
- limit ( limit the number of records)
In a SELECT query, the select clause, column name(s), and the table name is required (highlighted in orange below). The filter condition or the where clause are the conditions that must be met, along with the clauses for aggregation (group by) and sorting (order by). The optional parts of a select query are highlighted in green below.
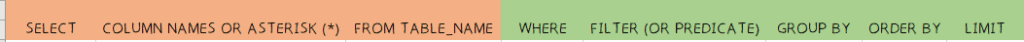
SQL Query Simple Examples
Query 1: How many kids scored higher than 85?
select name from kids_in_washington where score > 85
Results:
Name:
Tina
Jack
Dave
Brian
Query 2: Tell me everything about kids who like Blue color?
select * from kids_in_washington where Favorite_color = ‘Blue’